diff --git a/README.md b/README.md
index 0db1c30..02a0c75 100644
--- a/README.md
+++ b/README.md
@@ -24,26 +24,25 @@ To make it a collaborative project, you may add content throught pull requests o
To see a survey of RGBD datasets, I recommend to check out Michael Firman's [collection](http://www0.cs.ucl.ac.uk/staff/M.Firman//RGBDdatasets/) as well as the associated paper, [RGBD Datasets: Past, Present and Future](https://arxiv.org/pdf/1604.00999.pdf). Point Cloud Library also has a good dataset [catalogue](http://pointclouds.org/media/).
## Single Object Classification
-aaa
+to be added
## Multiple Objects Detection
-aaa
+to be added
## Part Segmentation
-aaa
+to be added
## 3D Synthesis/Reconstruction
-aaa
+_Parametric Morphable Model-based methods_
-## 3D Style Transfer
-### Parametric Morphable Model-based methods
A Morphable Model For The Synthesis Of 3D Faces (1999) [[Paper]](http://gravis.dmi.unibas.ch/publications/Sigg99/morphmod2.pdf)[[Github]](https://github.com/MichaelMure/3DMM)
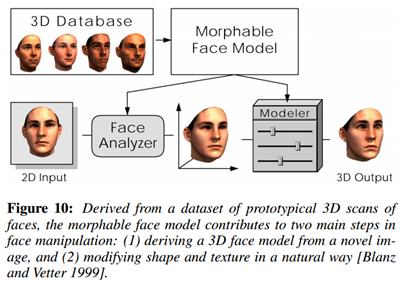
The Space of Human Body Shapes: Reconstruction and Parameterization from Range Scans (2003) [[Paper]](http://grail.cs.washington.edu/projects/digital-human/pub/allen03space-submit.pdf)

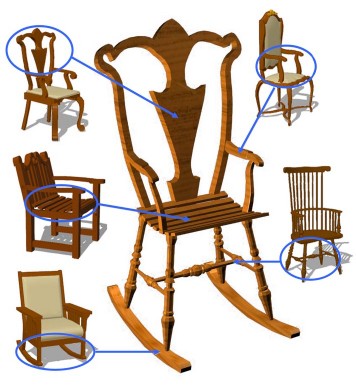
-### Part-based Template Learning methods
+_Part-based Template Learning methods_
+
Modeling by Example (2004) [[Paper]](http://www.cs.princeton.edu/~funk/sig04a.pdf)
@@ -87,11 +86,54 @@ aaa

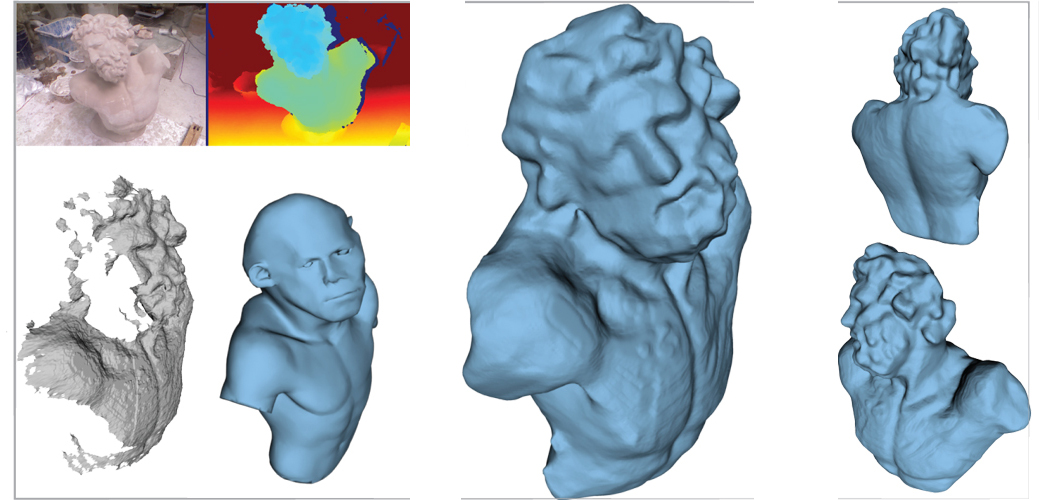
Shape Completion from a Single RGBD Image (2016) [[Paper]](http://www.kunzhou.net/2016/shapecompletion-tvcg16.pdf)
-
+
-### Deep Learning Methods
+_Deep Learning Methods_
+:camera: Learning to Generate Chairs, Tables and Cars with Convolutional Networks (2014) [[Paper]](https://arxiv.org/pdf/1411.5928.pdf)
+
+:game_die: Analysis and synthesis of 3D shape families via deep-learned generative models of surfaces (2015) [[Paper]](https://people.cs.umass.edu/~hbhuang/publications/bsm/)
+
+:camera: Multi-view 3D Models from Single Images with a Convolutional Network (2016) [[Paper]](https://arxiv.org/pdf/1511.06702.pdf) [[Code]](https://github.com/lmb-freiburg/mv3d)
+
-
+:camera: View Synthesis by Appearance Flow (2016) [[Paper]](https://people.eecs.berkeley.edu/~tinghuiz/papers/eccv16_appflow.pdf) [[Code]](https://github.com/tinghuiz/appearance-flow)
+
+
+:space_invader: Voxlets: Structured Prediction of Unobserved Voxels From a Single Depth Image (2016) [[Paper]](http://visual.cs.ucl.ac.uk/pubs/depthPrediction/http://visual.cs.ucl.ac.uk/pubs/depthPrediction/)
+
+
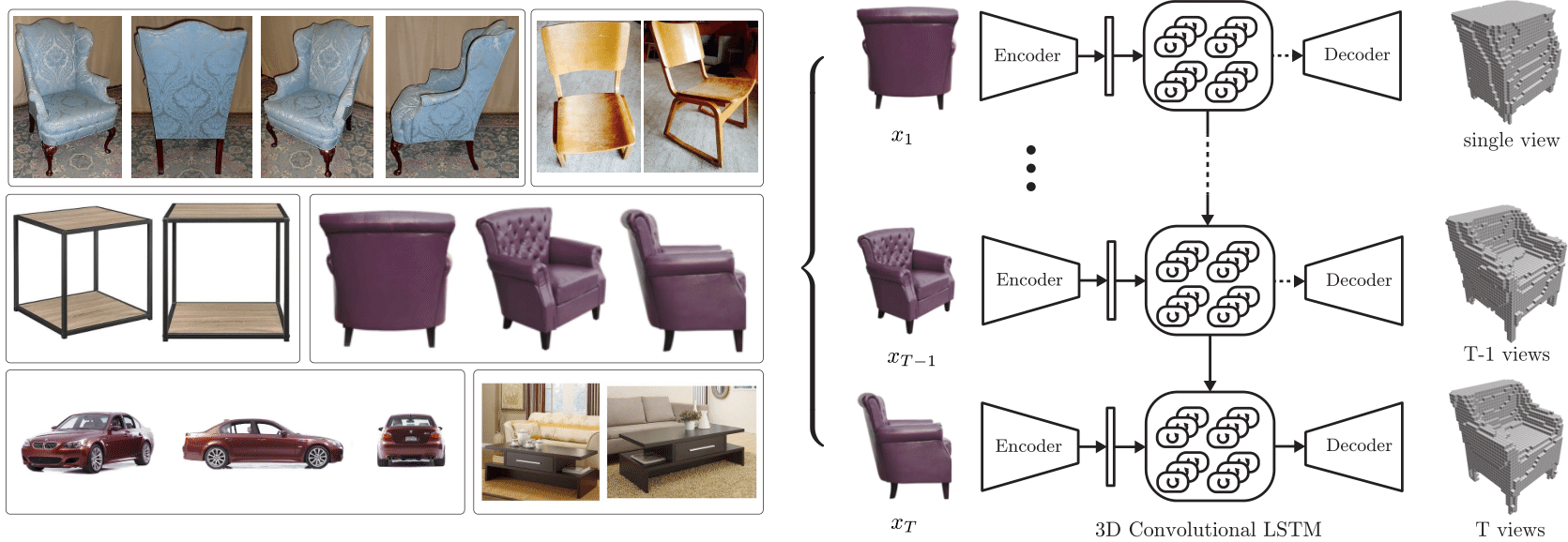
+:space_invader: 3D-R2N2: 3D Recurrent Reconstruction Neural Network (2016) [[Paper]](http://cvgl.stanford.edu/3d-r2n2/)
+
+
+:space_invader: TL-Embedding Network: Learning a Predictable and Generative Vector Representation for Objects (2016) [[Paper]](https://arxiv.org/pdf/1603.08637.pdf)
+
+
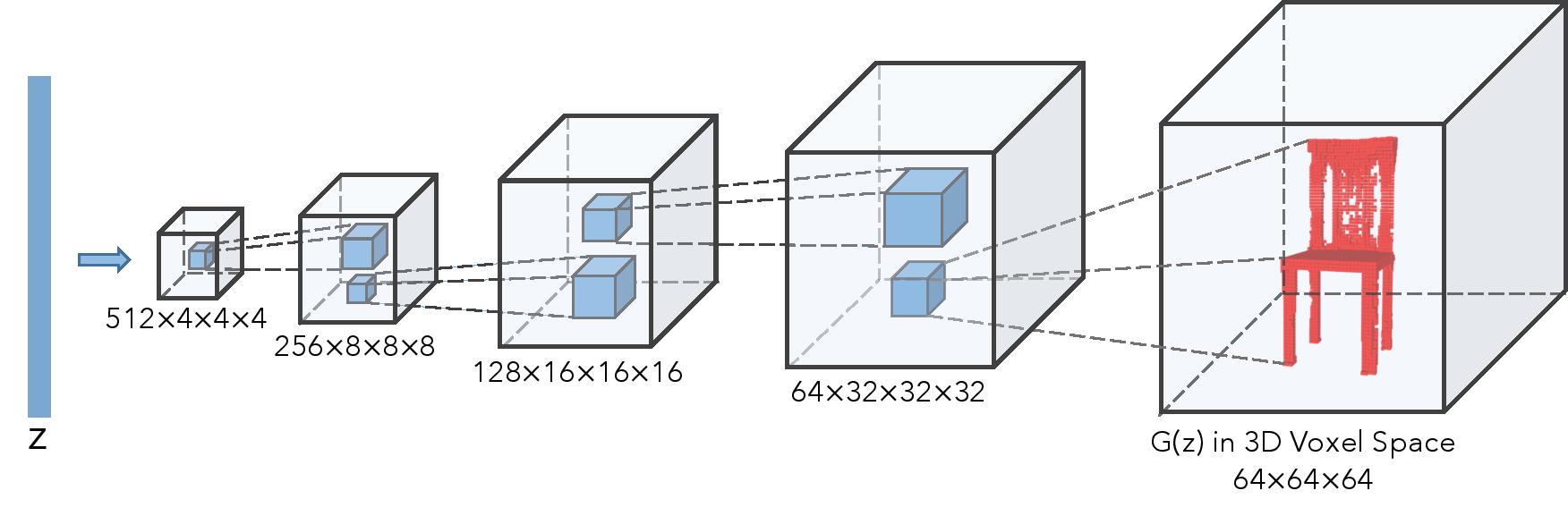
+:space_invader: 3D GAN: Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling (2016) [[Paper]](https://arxiv.org/pdf/1610.07584.pdf)
+
+
+:camera: Unsupervised Learning of 3D Structure from Images (2016) [[Paper]](https://arxiv.org/pdf/1607.00662.pdf)
+
+
+:camera: Multi-view Supervision for Single-view Reconstruction via Differentiable Ray Consistency (2017) [[Paper]](https://shubhtuls.github.io/drc/)
+
+
+:camera: Synthesizing 3D Shapes via Modeling Multi-View Depth Maps and Silhouettes with Deep Generative Networks (2017) [[Paper]](http://openaccess.thecvf.com/content_cvpr_2017/papers/Soltani_Synthesizing_3D_Shapes_CVPR_2017_paper.pdf)
+
+
+:space_invader: Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs (2017) [[Paper]](https://arxiv.org/pdf/1703.09438.pdf)
+
+
+:game_die: A Point Set Generation Network for 3D Object Reconstruction from a Single Image (2017) [[Paper]](http://ai.stanford.edu/~haosu/papers/SI2PC_arxiv_submit.pdf)
+
+
+:camera: Transformation-Grounded Image Generation Network for Novel 3D View Synthesis (2017) [[Paper]](http://www.cs.unc.edu/~eunbyung/tvsn/)
+
+
+:space_invader: Interactive 3D Modeling with a Generative Adversarial Network (2017) [[Paper]](https://arxiv.org/pdf/1706.05170.pdf)
+
+
+## 3D Style Transfer
+to be added