|
|
||
|---|---|---|
| doc | ||
| wav | ||
| README.md | ||
| codec2_model.py | ||
| eband_out.py | ||
| eband_synth_one.sh | ||
| eband_train.py | ||
| eband_vq_am.py | ||
| eband_vq_am_out.py | ||
| eband_vq_am_synth_one.sh | ||
| ebanddec_train.py | ||
| hyper_params.sh | ||
| impulse_test.sh | ||
| model_to_sparse.py | ||
| newamp1_train.py | ||
| rateK_train.py | ||
| test_vq_ewma.py | ||
| vq_kmeans.py | ||
| vq_kmeans_demo.py | ||
| vq_pager.py | ||
| vq_vae_conv1d_2stage.py | ||
| vq_vae_demo.py | ||
| vq_vae_demo_2stage.py | ||
| vq_vae_keras_mnist_example_orig.py | ||
| vq_vae_kmeans_conv1d.py | ||
| vq_vae_kmeans_conv1d_out.py | ||
| vq_vae_kmeans_demo.py | ||
| vq_vae_ratek.py | ||
| vq_vae_ratek_conv1d.py | ||
| vqvae_eband_synth_one.sh | ||
| vqvae_models.py | ||
| vqvae_synth_one.sh | ||
| vqvae_util.py | ||
README.md
Spectral Amplitude Quantisation using NNs
Experiments with time/frequency sample rate conversion and VQ-VAE (Vector Quantised Variational Autoencoder) for quantising the speech spectrum for vocoders.
This plot shows a VQ-VAE in action:
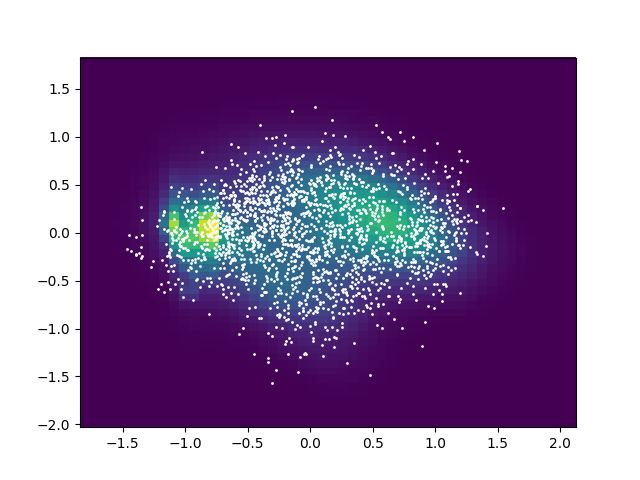 The plot is a 2D histogram of the encoder space, white dots are the stage 1 VQ entries. The 16 dimensional data has been reduced to 2 dimensions using PCA. The plot was produced by
The plot is a 2D histogram of the encoder space, white dots are the stage 1 VQ entries. The 16 dimensional data has been reduced to 2 dimensions using PCA. The plot was produced by vq_vae_conv1d_2stage.py
Themes and Key Points
- I'm a Neural Net Noob. As a way of learning I am trying out some NN ideas to solve problems I have faced before in specch coding.
- Currently using Keras 2.4.3 and Tensorflow 2.3.1
- For convenience I use Codec 2 (an old school, non NN vocoder) to "listen" to results from this work, however the cool kids are using VQ VAE with NN vocoders.
- I'm using regression - the NN estimates the actual log10(Am) values, not discrete PDFs.
- Making NN work with sparse, variable rate spectral magnitude vectors, using a sparse target and custom loss functions.
- Using NNs for decimation/interpolation (sub-sampling) in time, to reduce the frame rate and hence bit rate.
- Extending VQ VAE to two stage vector quantisation. Multi-stage VQ is commonly used in non-NN speech coding.
- The simulations (NN training and vector quantisation) works on mean square error in the log(Am) domain, which is equivalence to (i) variance (ii) and proportional to Spectral Distortion (SD) in dB^2 - which is very closely correlated to subjective quality. It trains in dB.
Scripts
| Script | Description | Useful? |
|---|---|---|
| codec2_model.py | Reading and writing Codec 2 model parameters | - |
| eband_train.py | Constant rate K to timing varying rate L, using LPCNet style K=14 vectors | No |
| ebanddec_train.py | Constant rate K to timing varying rate L, with decimation in time | No |
| eband_out.py | Generates Codec 2 output from NN trained in eband_train/ebanddec_train | No |
| newamp1_train.py | Similar to eband_train.py, constant rate K to timing varying rate L, using Codec 2 newamp1 K=20 vectors | No |
| vq_pager.py | Step through output rate K vectors | Yes |
| vq_vae_demo.py | Simple demo of VQVAE, nice visualisation of training in action | Cool demo |
| vq_kmeans.py | kmeans VQ training in TensorFlow | Yes |
| vq_kmeans_demo.py | Simple demo of kmeans VQ training in TF | Yes |
| vq_vae_kmeans_demo.py | Simple demo of kmeans VQVAE in TF | Yes |
| vq_vae_demo_2stage.py | vq_vae_demo.py extended to two stage VQ | Cool demo |
| vq_vae_ratek.py | Single stage VQ-VAE with single Dense layer | No |
| vq_vae_conv1d_2stage.py | Two stage VQ-VAE with two conv1D layers and simple/slow VQ training | Yes, reasonable spectral distortion, cool plots |
| vqvae_twostage.py | Two stage VQ VAE used by the scripts below | Yes |
| vq_vae_kmeans_conv1d.py | Two stage kmeans trained VQ-VAE with two conv1D layers | Yes |
| vq_vae_kmeans_conv1d_out.py | Generates output for Codec 2 from the NN trained above. Not great output at this stage :-) | Yes |
| vqvae_synth_one.sh | Script to generate output speech files from the above | Yes |
Amplitude Sample Rate Conversion Using Neural Nets
Some of the scripts in this repo (eband_*.py, newamp1_train.py) explore the use of Neural Networks (NN) in resampling between rate K and rate L for Codec 2.
Codec 2 models speech as a harmonic series of sine waves, each with it's own frequency, amplitude and phase. The frequencies are approximated as harmonics of the pitch or fundamental frequency. A reasonable model of the phases can be recovered from the amplitudes.
Accurate representation of the sine wave amplitudes {Am} m=1...L is important for good quality speech. The number of amplitudes in each frame L is dependent on the pitch L=P/2, which is time varying between (typically between L=10 and L=80). However for transmission at a fixed bit rate, a fixed number of parameters is desirable.
In earlier Codec 2 modes such as 3200 down to 1200, the amplitudes were represented using a fixed number of Linear Prediction Coefficients. In more recent modes such as 700C, the amplitudes Am are resampled to a fixed sample rate (K=20), and vector quantised for transmission. At the decoder, the rate K amplitude samples are resampled back to rate L for synthesis. The K=20 vectors use mel spaced sampling so these vectors are similar to the mel-spaced MFCCs used by the NN community.